J’aime à dire que l’évolution en informatique ne connait que très peu de ruptures et ressemble à une grande spirale dans laquelle les nouvelles technologies et approches ne sont que des reprises de plus anciennes que l’on a dépoussiéré et adapté aux attentes et au temps actuel ; c’est ce qui est appelé innovation. Les micro-services, le grand buzz de l’année 2015, n’échappent pas à cette règle. (On est friand aussi de buzz en informatique). Mais qu’est-ce que les micro-services ? En fait, rien de spécial. Ce n’est ni plus ni moins que le découpage des responsabilités des applications dans des services dédiés, sur un socle HTTP, et qui communiquent entre eux par messages. Du SOA ? Du REST ? … Oui, tout ça, mais ce n’est plus à la mode, il faut parler maintenant de micro-services.
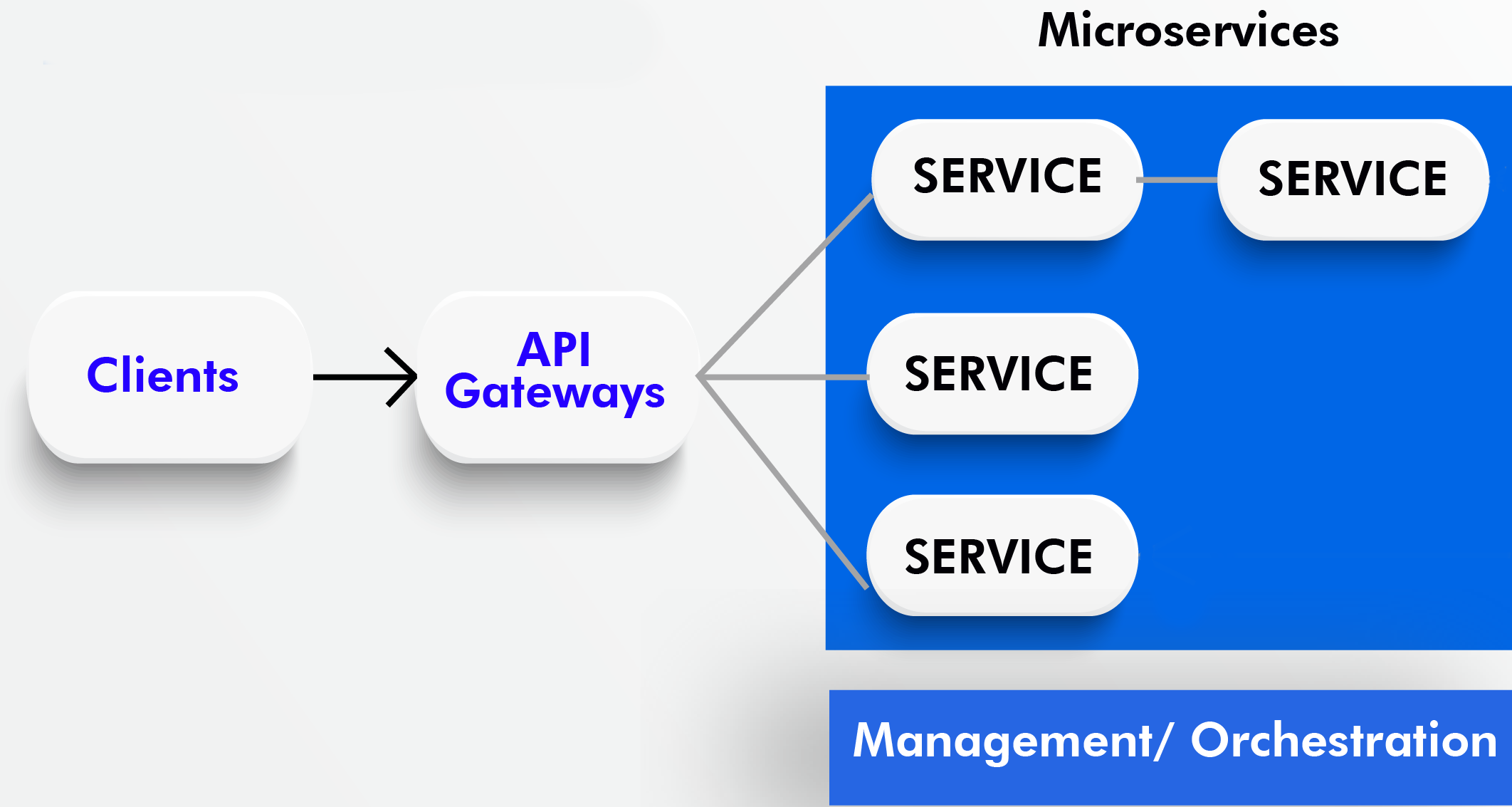
En fait, SOA, REST et les autres approches orientées services ne donnent aucun indication de comment doivent être architecturés les services entre eux. Ce sont les bonnes pratiques, l’expérience qui a guidé ces choix. Jusqu’à présent, dans les architectures orientées services, les applications, ou services, ne répondent qu’un seul métier mais peuvent couvrir plusieurs responsabilités et ils sont étagés les uns par rapport aux autres : les services les plus hauts étant ceux accédés par les utilisateurs et ceux les plus bas sont ceux qui manipulent les données métiers brutes et qui donc accèdent directement aux sources de données, avec une gateway en front et un aiguilleur/annuaire de services en transverse. L’approche architecturale micro-services quant à elle impose un schéma dans lequel chaque service ne doit couvrir qu’une seule responsabilité et peut, par conséquence, pour ce faire, accéder directement à une source de données et communiquer avec un ou plusieurs autres services. Attention donc au syndrome du plat de spaghetti ; les éditeurs d’ESB peuvent se frotter les mains. La grande difficulté avec ce style d’architecture, nous le voyons bien, est de savoir correctement urbaniser nos services mais aussi et surtout d’adapter cette urbanisation aux évolutions des besoins aussi bien techniques que métiers ; l’urbanisation devient prédondérante et peut rapidement devenir complexe. Pour ce coût, qui peut s’avérer assez cher, les avantages indéniables sont :
- une bien meilleur montée en charge verticale,
- une montée en charge horizontale qui peut être adaptée à chaque service,
- une meilleur isolation aux fautes,
- une meilleur productivité : les services étant relativement petits, ils sont plus faciles, pour les développeurs, à appréhender et à travailler dessus,
- une meilleur maintenance, chaque service ayant chacun leur propre cycle de vie,
- un déployement court,
- des services bien plus réutilisables entre différentes applications qu’auparavant.
Il semblerait donc que l’on a affaire à une nouvelle approche qui propose une meilleur façon d’architecturer les services. En fait elle n’est pas si nouvelle que ça et, comme le titre du billet le suggère, ça a voir avec le paradigme orienté objet.
La programmation orientée objet a été définie la première fois par Alan Kay à la fin des années 1960. Alan Kay, Dan Ingalls et les autres membres de l’équipe étaient à l’époque profondément impressionnés par la conception d’ARPANET, l’ancêtre d’Internet. Ce réseau mettait en relation des ordinateurs entre eux et permettait aux utilisateurs localisés dans des lieux géographiques différents de communiquer par le biais de protocoles donnés (mails, FTP, talk qui est l’ancêtre de la messagerie instantanée, etc.). Guidés par la célèbre formule de Bob Barton,
The basic principal of recursive design is to make the parts have the same power as the whole.
Alan Kay et les autres s’inspirèrent des principes derrières ARPANET dans leur conception d’un nouveau langage de programmation, Smalltalk. C’est de ce langage qu’est née la programmation orientée objet (n’en déplaise les contradicteurs qui voient Simula comme le premier langage orienté objet, ce qu’il n’est pas). Pour schématiser, dans ce paradigme de programmation, les objets, des entités logicielles de première classe, peuvent être vue comme des petits ordinateurs qui communiquent entre eux par envoie de messages (l’équivalent des protocoles dans ARPANET et donc d’Internet), et chaque objet ne convoit qu’une et une seule responsabilité.
A côté de ça, Smalltalk a été conçu pour être plus qu’un simple langage de programmation, mais un véritable environnement complet de développement et d’exécution. Il était déstiné à faire tourner le Dynabook, l’ancêtre du PC portable moderne ; ce ne devait pas être une application sur un OS mais l’OS même de la machine. En fait, dans sa conception, il n’y a pas de notions d’applications dans Smalltalk ; tout devait être objet et Smalltalk en était lui-même un (représentant la machine qu’il fait fonctionner). Si on devait donc faire le rapprochement entre le style d’architecture micro-services et le paradigme orienté objet, les services sont des objets réparties dans différentes VM (donc machines) et qui communiquent entre eux par messages (en utilisant les mécanismes et donc les protocoles sous jacent à l’architecture micro-services).
Il a fallu in fine attendre 2015 pour que l’approche véhiculée par la programmation orientée objet (celle d’Alan Kay, pas celle dénaturée de Ole-Johan Dahl et de Kristen Nygaard) finissent par s’appliquer dans la réalisation d’architectures d’applications distribuées. La différence est que l’approche micro-services est agnostique d’une quelconque technologie : les services peuvent être réalisés dans des langages et selon des paradigmes différents et qu’ils peuvent tourner en natif, dans des VM ou encore dans des conteneurs (Docker, …). La seule contrainte est le choix du mécanisme et du protocole d’échange de messages entre services qui doivent être commun et donc imposés pour tous ; en général, actuellement, c’est le protocole HTTP qui est choisi selon un mécanisme d’échange basé sur une approche REST.