
N’avez vous pas remarqué qu’il existe une approche orthodoxe dans la conception des logiciels client/serveur dont sont issue les applications web, et ceci quelque soit l’architecture sous-jacente (micro-services, n-tiers, monolithique, …) ? C’est une chose qui, depuis plusieurs années, m’a interpelé, et que j’ai identifié aussi bien dans des projets existants, dans des tutoriaux de frameworks ou bibliothèques, que dans des talks lors de conférences ou encore dans des kata. Elle est communément pratiquée sans une once d’un quelconque doute, sans réelle remise en cause. Je ne suis pas certain que ce soit le cas dans d’autres logiciels, comme celui des jeux par exemple. Mais qu’elle est donc cette approche ? Je la résumerai par le schéma simplifié ci-dessous qui reste valide aussi avec le modèle d’architecture logicielle hexagonale :
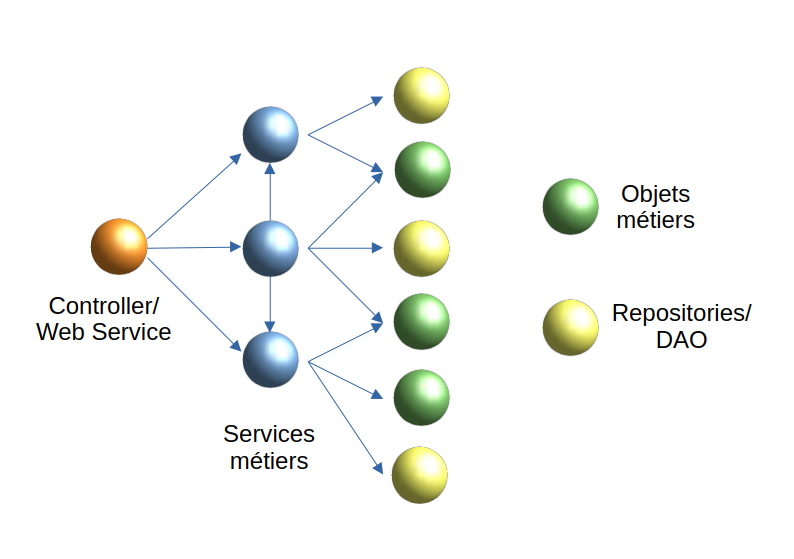
Le logiciel est conçu de façon à ce que les fonctionnalités métiers (mais aussi techniques) soient rassemblées dans des «services» qui, pour leur réalisation, vont manipuler des «objets métiers», voir techniques, et retourner le résultat sous forme d’agrégation d’objets métiers (ou les objets métiers eux-mêmes). Ces services vont faire appel soit à d’autres services, soit à la couche de persistance pour retrouver lesdits objets métiers (ou, de façon plus générale, à des services d’accès à des services distants). Voici peu ou prou le schéma de conception que l’on peut retrouver partout, avec parfois des variantes.
Cette orthodoxie n’est, à mes yeux, ni plus ni moins qu’une conception procédurale avec l’usage de techniques et de langages orientés objets. Et le Domain Driven Design d’Eric Evans ne remet pas en cause ce schéma. En effet, les services ne sont ni plus ni moins que des procédures déguisées sous forme d’objets. Leur dénomination, d’ailleurs, traduit cet état de fait avec leur suffix Service, Manager ou encore avec un nom plus fonctionnel comme par exemple, PublicationMove (lorsque les responsabilités des services sont découpés fonctionnellement selon une approche DDD).
Dans ce billet, je vais vous proposer une approche hétérodoxe, celle d’inverser les relations : au lieu que ce soient les services qui fassent appel aux objets métiers, je vous propose que ce soient au contraire ces derniers qui fassent appels aux services et … à la couche de persistance. Nous passerions donc, de mon point de vue, d’une approche de conception procédurale à une approche bien plus orientée objet dans laquelle les responsabilités métiers et fonctionnels sont exposées par les objets métiers eux-même. Par soucis de découplage, ceux-ci les délèguent de manière transparente aux services. Le contrôle du flot n’est donc plus dans les services mais dans les objets métiers eux-mêmes ; autrement dit on applique une IoC (Inversion of Control).
Afin de mieux appréhender cette approche de conception, je vous propose de l’illustrer avec un exemple simple en Java. Imaginons une GED (Gestion Electronique des Documents). Celle-ci manipule des contributions d’utilisateurs qui ont un contenu. Ce contenu peut être aussi bien un texte riche (contenu libre) qu’un formulaire (contenu structuré) par exemple. Une contribution peut être un document que l’utilisateur a téléversé dans le logiciel mais aussi une «publication» qui se trouve être un concept métier propre au domaine métier adressé par l’application : une publication a un contenu et rassemble des documents, appelés fichiers joints, auquels peuvent référer son contenu.

L’approche procédurale (ou orientée service)
Selon l’orthodoxie, nous aurions un «service» pour manipuler les publications pour le compte d’un service REST ou d’un contrôleur Web par exemple :
public class PublicationService {
private final PublicationRepository repository;
private final ContentService contentService;
public PublicationService(PublicationRepository repository,
ContentService contentService) {
this.repository = repository;
this.contentService = contentService;
}
public Optional<Publication> getPublication(String id) {
return repository.findById(id);
}
public Publication createPublication(PublicationDetails details) {
checkAuthorNotNull(details.author);
Publication publication = Publication.builder()
.title(details.title)
.description(details.description)
.created(details.author, Instant.now())
.content(details.content)
.build();
return savePublication(publication);
}
public Publication updatePublication(String pubId, PublicationDetails details) {
Publication actual = repository.findById(pubId)
.orElseThrow(() -> new NotFoundException("Publication not found with id " + pubId));
checkAuthorNotNull(details.author);
actual.setLastModification(details.author, Instant.now());
actual.setTitle(details.title);
actual.setDescription(details.description);
actual.setContent(details.content);
return savePublication(actual);
}
private Publication savePublication(Publication publication) {
return Transaction.performInOne(() -> {
saveContent(publication);
return repository.save(publication);
});
}
private void saveContent(Publication publication) {
if (publication.getContent() != null) {
Content content = publication.getContent();
publication.setContent(contentService.createContent(content));
}
}
private void checkAuthorNotNull(User author) {
Objects.requireNonNull(author, "Author of a publication must not be null");
}
}
Le service ci-dessus gère la construction et la mise à jour des Publications, ce qui lui permet de contrôler que les données de celles-ci soient correctes. Les données des publications sont donc passées par le biais de DTO sous forme de record ici, permettant ainsi de détacher des clients la responsabilité de construction et de mise à jour directe des objets métiers, mais aussi de pouvoir être utilisé aussi bien par une API Web sous forme de ressources REST que d’un front de contrôleurs Web pour des pages HTML. (Une autre façon de faire, plus usuelle, est de ne pas utiliser de DTO ici mais directement l’objet métier, ce qui permet une économie de code au risque d’une dilution potentielle de responsabilités et des contrôles entre le service et l’appelant.)
Quant aux contenus des publications, sachant que ceux-ci peuvent être de types différents (texte riche, formulaire, etc.), leur gestion est délégué à un service dédié :
public class ContentService {
private final SpecificContentServiceProvider serviceProvider =
new SpecificContentServiceProvider();
public Content createContent(Content content) {
return Transaction.performInOne(() ->
serviceProvider.provides(content.getType()).createContent(content));
}
...
}
Ce service est un adapteur qui encapsule la gestion des contenus selon leur type spécifique. Ainsi donc, il délègue lui-même la fonctionnalité au service qui gère spécifiquement le type de contenus attendu et correspondant au contenu passé en argument.
Avec cette approche orientée service, la classe Publication serait anémique avec juste des méthodes pour accéder et mettre à jour ses propriétés, potentiellement aussi avec des légers contrôles internes d’intégrité, et les appels métiers par les clients se feraient donc directement auprès du service associé :
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) {
var publicationService = getService(PublicationService.class);
perform(new OperationContext(req, resp, HttpServletResponse.SC_CREATED), () -> {
var entity = WebEntity.fromJson(getReader(req), PublicationWebEntity.class);
PublicationDetails details = entity.asPublicationDetails()
.setAuthor(getCurrentRequester());
Publication publication = publicationService.createPublication(details);
return webEntityWithURIs(req, publication);
});
}
PublicationWebEntity est un DTO qui filtre les propriétés de Publication à exposer et qui en ajoute de supplémentaires (URI de la ressource représentée, opérations Web supportées, etc.) à destination de l’appelant HTTP.
Ok. Maintenant, envisageons la gestion des fichiers joints. Une publication, dans notre domaine métier, est une contribution d’utilisateurs à qui peuvent être joints des documents annexes. Toutefois, nous pouvons très bien envisager d’autres types de contributions à qui puissent aussi être joints des documents. Aussi, le service de gestion des fichiers joints peut être envisagé comme un service transverse :
public class AttachmentService {
private final AttachmentRepository repository;
private final FileStore fileStore;
public AttachmentService(FileStore fileStore, AttachmentRepository repository) {
this.repository = repository;
this.fileStore = fileStore;
}
public Set<Attachment> getContributionAttachments(String contributionId) {
return repository.findByContributionId(contributionId);
}
public Attachment createAttachment(DocumentDetails details, Contribution contribution) {
return Transaction.performInOne(() -> {
checkUploaderNotNull(details.author);
FileContent content = storeDocument(details.document);
Attachment attachment = Attachment.attach(content, contribution)
.title(details.title)
.description(details.description)
.creation(details.author, Instant.now())
.build();
return repository.save(attachment);
});
}
public Attachment updateAttachment(String attachmentId, DocumentDetails details) {
return Transaction.performInOne(() -> {
Attachment actual = repository.findById(attachmentId)
.orElseThrow(() ->
new NotFoundException("Attachment not found with id " + attachmentId));
checkUploaderNotNull(details.author);
FileContent content = storeDocument(details.document);
actual.setContent(content);
actual.setModification(details.author, Instant.now());
actual.setTitle(details.title);
actual.setDescription(details.description);
return repository.save(actual);
});
}
private FileContent storeDocument(File document) {
Path docPath = fileStore.store(document);
return new FileContent(docPath);
}
private void checkUploaderNotNull(User uploader) {
Objects.requireNonNull(uploader, "Uploader of a file must not be null");
}
}
L’objet FileStore est un service technique qui gère pour nous le stockage des fichiers sur le serveur, qu’ils soient générés par l’application même ou téléversés par les utilisateurs. Il abstrait l’emplacement de ceux-ci sur le système de fichiers et leur gestion pour le compte de l’application. Il peut aussi abstraire une base de documents à structure arborescente.
Comme les publications acceptent les fichiers joints, nous pouvons imaginer la responsabilité de gestion de ceux-ci pour les publications directement dans la classe PublicationService qui déléguerait alors celle-ci au AttachmentService. Nous pouvons aussi transférer ce comportement à un service de plus haut niveau qui prend aussi en compte les autres responsabilités comme celui des placements des publications dans un dossier de la GED :
public Publication createPublication(PublicationDetails pubDetails, DocumentDetails... someDocDetails) {
return Transaction.performInOne(() -> {
Publication publication = publicationService.createPublication(pubDetails);
for (DocumentDetails docDetails: someDocDetails) {
Attachment attachment = attachmentService.createAttachment(docDetails, publication);
publication.getAttachments().add(attachment);
}
return publication;
});
}
public Set<Publication> getDirectPublicationsInFolder(String folderId) {
var folder = folderService.getFolder(folderId)
.orElseThrow(() ->
new NotFoundException("Folder not found with id " + folderId));
var publications = publicationService.getPublicationsInFolder(folder.getId());
for (Publication publication: publications) {
var attachments = attachmentService.getAttachments(publication.getId());
publication.getAttachments().addAll(attachments);
}
return publications;
}
Les deux approches sont évidemment correctes et l’adoption de l’une par rapport à l’autre dépend du contexte métier et applicatif. (Dans notre cas, la solution du service de plus haut niveau est overkill.)
L’approche orientée objet
Maintenant que nous avons présenté, au travers de notre exemple simplifié de GED, comment aurait été conçu le code selon l’orthodoxie, je vous propose la solution alternative suivante qui, à mes yeux, adopte une approche bien plus orientée objet.
Cette fois-ci, le code client n’invoque plus les services pour accomplir les tâches métiers mais directement les objets métiers :
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) {
perform(new OperationContext(req, resp, HttpServletResponse.SC_CREATED), () -> {
var entity = WebEntity.fromJson(getReader(req), PublicationWebEntity.class);
Publication publication = entity.toPublicationWithAsAuthor(getCurrentRequester());
publication.save();
return webEntityWithURIs(req, publication);
});
}
Comme précédemment, nous avons notre PublicationWebEntity mais, au lieu de retourner le DTO PublicationDetails avec les données de la publication, elle retourne directement l’objet Publication avec les données métiers :
public Publication toPublication() {
return Publication.builder()
.title(title)
.description(description)
.createdBy(creator == null ? null : creator.toUser())
.lastModifiedBy(modifier == null ? null : modifier.toUser())
.build();
}
public Publication toPublicationWithAsAuthor(User author) {
return Publication.builder()
.title(title)
.description(description)
.createdBy(author)
.lastModifiedBy(author)
.build();
}
Et Publication délègue la persistance de ses instances au service PublicationStore :
class PublicationStore {
private final PublicationRepository repository;
private final Publication publication;
PublicationStore(Publication publication) {
this.publication = publication;
this.repository = PublicationRepository.getInstance();
}
public void save() {
Transaction.performInOne(() -> {
if (publication.getId() == null) {
checkAuthorNotNull(publication.getCreator());
publication.setCreationDate(Instant.now());
publication.setModification(publication.getCreator(), publication.getCreationDate());
savePublication(publication);
} else {
checkAuthorNotNull(publication.getLastModifier());
savePublication(publication);
}
});
}
public void delete() {
Transaction.performInOne(() -> {
repository.delete(publication);
});
}
private void savePublication() {
saveContent(publication);
repository.save(publication);
}
private void saveContent() {
if (publication.getContent() != null) {
Content content = publication.getContent();
content.save();
}
}
private void checkAuthorNotNull(User author) {
Objects.requireNonNull(author, "Author of a publication must not be null");
}
}
Dans la présentation donnée ici, chaque instance de PublicationStore est propre à une publication donnée. Toutefois, il peut être conçu de façon à être transverse à toute publication et, dans cette optique, ses méthodes devront être définis avec comme paramètre la publication sur laquelle l’opération doit se faire.
Ici, les contraintes d’integrité et autres conditions sont validées par les objets métiers, ou plus exactement, ici, elles sont déléguées au service métier PublicationStore. Avec l’approche orientée objet , ces validations sont naturellements codées côté objet métier, là où avec l’approche orthodoxe le doute peut demeurer entre l’appelant, les services métiers et les objets métiers ; il n’est alors pas râre de rencontrer une dilution de ses validations dans différentes parties du code.
De la même manière, l’obtention de publications se fait par délégation à un service dédié, le requêteur de publications, qui est fournit directement par la classe Publication :
public class PublicationRequester {
private final PublicationRepository repository;
PublicationRequester() {
this.repository = PublicationRepository.getInstance();
}
public Optional<Publication> getById(String id) {
Objects.requireNonNull(id, "The publication id must not be null!");
return repository.findById(toPersistenceId(id));
}
public Set<Publication> getByAuthor(User author) {
Objects.requireNonNull(author, "The author must not be null!");
return repository.findByAuthor(author.getId());
}
...
}
Et avec lequel la classe Publication peut offrir des raccourcis :
public class Publication implements AutoPersistentContribution {
...
public static Optional<Publication> get(String id) {
return requester().getById(id);
}
public static Publication getOrFail(String id) {
return get(id)
.orElseThrow(() -> new NotFoundException("Publication not found with id " + id));
}
public static Set<Publication> getAll() {
return requester().getAll();
}
...
}
Ce qui donnerait avec notre servlet :
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) {
String id = req.getParameter(PUB_ID);
perform(new OperationContext(req, resp, HttpServletResponse.SC_OK), () -> {
if (id == null || id.isBlank()) {
Set<Publication> publications = Publication.getAll();
return new WebEntitiesArray(
publications.stream()
.map(p -> webEntityWithURIs(req, p))
.toList());
} else {
Publication publication = Publication.getOrFail(id);
return webEntityWithURIs(req, publication);
}
});
}
Ok. Maintenant abordons les fichiers joints. Selon notre approche, comme ces derniers sont associés aux publications, nous devrions donc pouvoir les manipuler par l’intermédiaire de la publication à laquelle ils sont joints et ceci de façon transparente pour l’appelant. Par exemple, dans le cas de joindre par le Web un fichier à une publication :
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) {
String pubId = req.getParameter(PUB_ID);
perform(new OperationContext(req, resp, HttpServletResponse.SC_CREATED), () -> {
checkParameter(pubId, "Missing publication id parameter");
var publication = Publication.getOrFail(pubId);
var document = fetchUploadedFile(req);
var attachment = Attachment.attach(document)
.to(publication)
.withTitle(req.getParameter("title"))
.withDescription(req.getParameter("description"))
.authoredBy(getCurrentRequester())
.build();
publication.attachments().add(attachment);
publication.save();
return webEntityWithURIs(req, publication.getId(), attachment);
});
}
Pour éviter de polluer notre objet métier Publication avec les mécanismes de gestion des fichiers joints, celui-ci délègue ce rôle à un service dédié, appelé Attachments, et que renvoie justement la méthode Publication#attachments(). Notre service Attachments n’est ni plus ni moins que la réification de notre classe d’association éponyme dans notre diagramme de classe ! Et par conséquent, ce service est donc lié à la contribution pour laquelle il gère les fichiers qui lui sont joints :
public class Attachments<T extends Contribution> {
private final AttachmentRepository repository = AttachmentRepository.getInstance();
private final T contribution;
private final Cache cache = new Cache();
public Attachments(T contribution) {
this.contribution = contribution;
}
public void add(Attachment attachment) {
checkUploaderNotNull(attachment.getCreator());
contribution.modifiedBy(attachment.getCreator());
cache.add(attachment);
}
public Optional<Attachment> get(String id) {
if (cache.isNotComplete()) {
repository.findById(id).ifPresent(cache::add);
}
return cache.content().stream()
.filter(a -> a.getId().equals(id))
.findFirst();
}
public Attachment getOrFail(String id) {
return get(id)
.orElseThrow(() -> new NotFoundException("Attachment not found: " + id));
}
public List<Attachment> all() {
if (cache.isNotComplete()) {
var attachments = repository.findByContributionId(contribution.getId());
cache.fill(attachments);
}
return List.copyOf(cache.content());
}
public Stream<Attachment> stream() {
return all().stream();
}
public void save() {
Transaction.performInOne(() -> {
for (Attachment attachment : cache.content()) {
attachment.getContent().save();
repository.save(attachment);
}
});
}
public T getContribution() {
return contribution;
}
private void checkUploaderNotNull(User uploader) {
Objects.requireNonNull(uploader, "Uploader of a file must not be null");
}
private static class Cache {
private final List<Attachment> attachments = new ArrayList<>();
private boolean complete = false;
public void add(Attachment attachment) {
attachments.add(attachment);
}
public void fill(Set<Attachment> allAttachments) {
attachments.clear();
attachments.addAll(allAttachments);
complete = true;
}
public boolean isNotComplete() {
return !complete;
}
public List<Attachment> content() {
return attachments;
}
}
}
La méthode Attachments#save() est appelé par le service PublicationStore lorsque la sauvegarde des modifications de la publication est invoquée ; l’appel se fait dans la méthode privée PublicationStore#savePublication() :
private void savePublication() {
saveContent(publication);
publication.attachments().save();
repository.save(publication);
}
Cette approche orientée objet est, de mon point de vue, d’une part pour l’utilisateur plus naturelle, et, d’autre part pour le concepteur plus fluide et propre. En effet, étant directement dérivé du design (comme on a pu le voir avec la classe d’association Attachments d’avec le diagramme de classe), sans transformation, il n’y a alors plus besoin de commuter de modèle lors du développement, et donc de commuter aussi notre façon de penser, de raisonner, ce qui évite donc de perdre de l’énergie, de s’embrouiller, et de se poser des questions quant aux responsabilités. Les choses deviennent plus claires : à la lecture et à l’écriture du code. Illustration. Vous voulez déplacer une publication dans un autre dossier :
Publication.getOrFail(publicationId)
.moveInto(Folder.getOrFail(folderId));
vous souhaitez définir une plage de temps pendant laquelle la publication est automatiquement visible et à la suite de laquelle automatiquement elle n’est plus accessible (mise à part au gestionnaire et aux auteurs de ladite publication) :
Publication.getOrFail(publicationId)
.scheduleVisibilityOn(Period.between(startDate, endDate));
et chacune de ses méthodes délèguent en fait leur réalisation à un service dédié mais de façon transparente pour l’appelant.
Toutefois, parce qu’orthodoxe, les bibliothèques et frameworks logiciels sont dans la majeur partie conçus avec l’approche orientée service. Ce qui fait que vouloir appliquer une approche plus orientée objet (ou tout autre approche d’ailleurs, comme celle fonctionnelle) devient plus délicat. Nous pouvons clairement le percevoir avec, par exemple, le framework Spring et en particulier avec les outils d’injection de dépendances (ou IoD).
L’injection de dépendances
Maintenant, abordons les choses qui fachent, je veux parler ici de l’injection de dépendances : comment réaliser celle-ci avec l’approche orientée objet telle que illustrée ci-dessus ? Autrement dit, comment injecter les implémentations des services et des objets d’accès à la persistance aux entités et agrégats métiers sachant que ceux-ci sont des objets construits «à la main» ?
Dans l’écosystème Java, les mécanismes dits d’injection de dépendances réalisent deux fonctions principales : la gestion du cycle de vie des objets pris en charge (appelés «beans» dans le jargon java) et l’injection des dépendances desdits objets. Ces beans sont alors enregistrés dans un conteneur dit IoD, ou tout simplement de beans, et la satisfaction des dépendances sont résolues soit à la compilation (comme avec Dagger ou Micronaut), soit au démarrage de l’application (comme avec Spring ou CDI). Ainsi donc, pour que les dépendances d’un objet soit prises en charge, il faut que d’une part le cycle de vie de cet objet soit géré par le conteneur et que d’autre part celui de ses dépendances aussi. Or, nous le voyons bien, ce n’est pas le cas des objets métiers issus de la persistance ou construits par agrégats d’autres objets métiers.
Il est donc nécessaire de trouver pour ces objets un moyen d’accès aux beans du container de façon soit statique (résolution des dépendances statiques à la compilation), soit paresseuse (résolution des dépendances à la demande au runtime). Et ce n’est pas gagné. En effet, les frameworks d’IoD reposent justement sur la propriété implicite que les services, qu’ils soient métiers ou techniques (je range la persistance dedans), sont des citoyens de première classe, une caractéristique propre à l’orthodoxie. C’est à dire que ce sont les services qui sont manipulés en première place et les entités et agrégats métiers ne sont que des véhicules des données manipulées par ces derniers.
Or, il en est toute autre avec l’approche orientée objet : les citoyens de première classe sont les objets métiers, et les services ne sont donc accessibles que par ceux-ci. Aussi, naturellement l’obtention des services par les objets métiers se fait donc soit en les construisant directement, soit par application de design patterns (comme par exemple Singleton, Factory ou Strategy). Dans ce contexte, l’utilisation du Java Service Provider Interface est une solution qui peut faciliter grandement l’application des design patterns et remplacer avantageusement un mécansime d’injection de dépendances exterieur. Il est toutefois possible d’écrire soit même son propre mécanisme d’IoD, de façon simple et adapté à notre contexte et à notre approche hérérodoxe.
Ok, mais si on veut utiliser un mécanisme existant d’injection de dépendances, comment faire avec l’approche orientée objet ? je vais ici aborder les deux frameworks les plus en vogue dans le monde Java, à savoir CDI et Spring.
Avec CDI, rien de plus simple. CDI est avant tout une spécification Jakarta EE (anciennement JEE) et son API expose un objet CDI qui donne accès programmatiquement au conteneur de beans sous-jacent à l’implémentation de la spécification. A Silverpeas, nous avons défini une interface BeanContainer pour abstraire le framework d’injection de dépendances utilisé et son implémentation pour CDI donne ceci :
public class CDIContainer implements BeanContainer {
@SuppressWarnings("unchecked")
@Override
public <T> Optional<T> getBeanByName(final String name) throws IllegalStateException {
BeanManager beanManager = CDI.current().getBeanManager();
try {
//noinspection RedundantCast,rawtypes
Bean<T> bean = beanManager.resolve((Set) beanManager.getBeans(name));
if (bean == null) {
return Optional.empty();
}
CreationalContext<T> ctx = beanManager.createCreationalContext(bean);
Type type = bean.getTypes()
.stream()
.findFirst()
.orElseThrow(() -> new ExpectationViolationException("The bean " + name +
" doesn't satisfy any managed type"));
return Optional.ofNullable((T) beanManager.getReference(bean, type, ctx));
} catch (AmbiguousResolutionException e) {
throw new MultipleCandidateException(e.getMessage(), e);
} catch (IllegalArgumentException e) {
// the figured out type of the bean is incorrect. This shouldn't happen as it is the one
// CDI provides us for the fetched bean.
return Optional.empty();
}
}
@SuppressWarnings("unchecked")
@Override
public <T> Optional<T> getBeanByType(final Class<T> type, Annotation... qualifiers)
throws IllegalStateException {
BeanManager beanManager = CDI.current().getBeanManager();
try {
//noinspection RedundantCast,rawtypes
Bean<T> bean = beanManager.resolve((Set) beanManager.getBeans(type, qualifiers));
if (bean == null) {
return Optional.empty();
}
CreationalContext<T> ctx = beanManager.createCreationalContext(bean);
return Optional.ofNullable((T) beanManager.getReference(bean, type, ctx));
} catch (AmbiguousResolutionException e) {
throw new MultipleCandidateException(e.getMessage(), e);
} catch (IllegalArgumentException e) {
// if the annotation isn't a qualifier (the type of the bean should be the one we
// are asking)
throw new ExpectationViolationException(e.getMessage(), e);
}
}
@SuppressWarnings("unchecked")
@Override
public <T> Set<T> getAllBeansByType(final Class<T> type, Annotation... qualifiers) {
BeanManager beanManager = CDI.current().getBeanManager();
try {
return beanManager.getBeans(type, qualifiers).stream().map(bean -> {
CreationalContext<?> ctx = beanManager.createCreationalContext(bean);
return (T) beanManager.getReference(bean, type, ctx);
})
.collect(Collectors.toSet());
} catch (IllegalArgumentException e) {
// if the annotation isn't a qualifier
throw new ExpectationViolationException(e.getMessage(), e);
}
}
}
et l’accès à un bean du conteneur, comme un repository ou un service, par un objet métier, peut alors se faire comme suit :
public class Publication implements AutoPersistentContribution {
...
@Override
public void save() {
PublicationStore store = ManagedBeanProvider.getInstance()
.getManagedBean(PublicationStore.class);
store.save(this);
}
@Override
public void delete() {
PublicationStore store = ManagedBeanProvider.getInstance()
.getManagedBean(PublicationStore.class);
store.delete(this);
}
...
}
où ManagedBeanProvider est un singleton non géré par CDI et qui, à sa construction, par utilisation du mécanisme du Java Service Loader Interface, récupère une instance de l’implémentation de BeanContainer disponible.
Le revert de ceci est que comme l’appel au bean géré par CDI se fait de façon paresseuse à la demande, nous payons l’overhead de l’appel à CDI qui est loin d’être négligeable en forte charge. C’est pourquoi nous avons ajouté dans le code de la classe ManagedBeanProvider un cache pour y garder les uniques instances des singletons.
Quant au framework Spring, le point délicat est de pouvoir récupérer l’instance d’ApplicationContext qui a été créée et initialisée par Spring au démarrage de l’application. C’est ce dernier qui offre l’accès au conteneur de beans. L’idée est alors d’enregistrer ce contexte applicatif, afin de donner accès à celui-ci, dans l’un de de nos objets, seule instance d’un singleton et non géré par Spring. Par exemple dans un objet ApplicationContextProvider à partir duquel notre implémentation de BeanContainer puisse y avoir accès pour offrir ses services d’accès aux beans gérés par Spring.
Avec SpringBoot, tout se fait directement dans le point d’entrée du programme :
@SpringBootApplication
public class GEDApplication {
public static void main(String[] args) {
var ctx = SpringApplication.run(GEDApplication.class, args);
ApplicationContextProvider.getInstance().setApplicationContext(ctx);
}
}
A partir de là, il suffit de fournir une implémentation de l’interface BeanContainer vu précédemment :
public class SpringContainer implements BeanContainer {
private final ApplicationContext ctx;
public SpringContainer() {
ctx = ApplicationContextProvider.getInstance().getApplicationContext();
}
@SuppressWarnings("unchecked")
@Override
public <T> Optional<T> getBeanByName(String name) {
try {
return Optional.of((T) ctx.getBean(name));
} catch (NoUniqueBeanDefinitionException e) {
throw new MultipleCandidateException(e.getMessage(), e);
} catch (NoSuchBeanDefinitionException e) {
return Optional.empty();
} catch (ClassCastException e) {
throw new ExpectationViolationException("The bean " + name +
" doesn't satisfy any managed type");
} catch (BeansException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
@Override
public <T> Optional<T> getBeanByType(final Class<T> type, Annotation... qualifiers) {
try {
List<Set<T>> beanSets = Stream.of(qualifiers)
.map(q ->
ctx.getBeansWithAnnotation(q.getClass()).values().stream()
.filter(bean -> type.isAssignableFrom(bean.getClass()))
.map(type::cast)
.collect(Collectors.toSet()))
.toList();
if (beanSets.isEmpty()) {
return Optional.of(ctx.getBean(type));
}
var s1 = beanSets.getFirst();
for (int i = 1; i < beanSets.size(); i++) {
s1.retainAll(beanSets.get(i));
}
if (s1.isEmpty()) {
return Optional.empty();
}
if (s1.size() == 1) {
return Optional.of((T) s1.iterator().next());
}
String listOfQualifiers = Stream.of(qualifiers)
.map(Annotation::getClass)
.map(Class::getName)
.collect(Collectors.joining(", "));
throw new MultipleCandidateException("Multiple beans of type " + type +
" and qualified by " + listOfQualifiers);
} catch (NoUniqueBeanDefinitionException e) {
throw new MultipleCandidateException(e.getMessage(), e);
} catch (NoSuchBeanDefinitionException e) {
return Optional.empty();
} catch (BeansException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
@Override
public <T> Set<T> getAllBeansByType(final Class<T> type, Annotation... qualifiers) {
try {
List<Set<T>> beanSets = Stream.of(qualifiers)
.map(q ->
ctx.getBeansWithAnnotation(q.getClass()).values().stream()
.filter(bean -> type.isAssignableFrom(bean.getClass()))
.map(type::cast)
.collect(Collectors.toSet()))
.toList();
if (beanSets.isEmpty()) {
return new HashSet<>(ctx.getBeansOfType(type).values());
}
var s1 = beanSets.getFirst();
for (int i = 1; i < beanSets.size(); i++) {
s1.retainAll(beanSets.get(i));
}
return s1;
} catch (BeansException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}
Avec Spring au-dessus d’un conteneur de Servlet, il faut utiliser Spring MVC qui permet, via notre propre implémentation de son interface WebApplicationInitializer ou de l’une de ses implémentations abstraites (comme AbstractDispatcherServletInitializer par exemple), de construire une instance de ApplicationContext et par conséquent de la récupérer. Par exemple :
public class GEDApplicationInitializer implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext servletContext) {
AnnotationConfigWebApplicationContext context = new AnnotationConfigWebApplicationContext()
ApplicationContextProvider.getInstance().setApplicationContext(ctx);
...
}
}
(Pour plus d’information, je vous recommande de consulter la documentation à ce sujet.)
Dans tous les cas, il faut s’assurer que l’objet ApplicationContext soit déjà enregistré auprès de ApplicationContextProvider lorsque le conteneur SpringContainer est instancié par le Java Service Loader Interface à l’initialisation de la seule instance de ManagedBeanProvider.
Conclusion
J’espère que cet article, un peu plus long que d’habitude, vous a quelque peu titillé, à défaut de vous avoir convaincu, sur l’aspect discutable de l’approche en vigueur dans le développement d’application Web ou de micro-services, et de la force que présente une approche bien plus orientée objet proposée et illustrée ici. Et que cette approche est possible aussi, avec un peu de gymnastique, avec des frameworks existants d’IoD comme CDI ou Spring.