Dans ce premier billet de l’année 2018, je vais m’essayer de vous présenter ce que sont les foncteurs, les foncteurs applicatifs et les monades de façon simple, sans étalage de la théorie mathématique derrière (celle des catégories) dont, de toute manière, je ne maîtrise pas. Bien que ce soient des constructions utilisées dans la programmation fonctionnelle, elles peuvent aussi être utilisées dans d’autres approches de programmation et avec d’autres langages que ceux fonctionnels. C’est pourquoi je présenterai chacun des concepts non seulement avec du code en Haskell mais aussi en Java.
Tout paradigme de programmation définit des règles de composition, ceci afin de mieux structurer le code, faciliter son écriture et sa maintenance, et pour éviter de lourdes duplications de code. Ces règles permettent de représenter des concepts, des abstractions de plus haut niveau, par la composition de briques logicielles plus techiques ou d’abstractions plus faibles. Dans les langages dits impératifs, les règles de composition sont centrées sur les structures de données ; par exemple, l’extension de classes ou de modules. Dans le paradigme fonctionnel, l’accent est mit sur la composition de fonctions ; l’exemple le plus connu est le fameux «f rond g» qui permet d’obtenir une nouvelle fonction par connection de deux autres (l’entrée d’une fonction est connectée à la sortie d’une autre). C’est probablement la raison principale pour laquelle le nom de fonctionnel est donné à cette approche de programmation.
Les foncteurs (functors), les foncteurs applicatifs (applicatives) et les monades (monads) ne sont en faits que d’autres constructions de composition, d’abstraction plus élevées. Elles sont inspirées de la théorie des catégories en Mathématiques, d’où leur nom, mais ne nécessitent pas en réalité une connaissance de celle-ci pour pouvoir les utiliser. Elles sont en général définies dans les langages fonctionnels à l’aide des types algébriques. Leur objectif est, grosso-modo, de pouvoir chaîner des fonctions par le biais d’objets transportant un contexte informationnel ou calculatoire et de conserver celui-ci au travers de cet enchaînement. L’illustration la plus connue est le resultat des opérations à effet de bord comme, par exemple, l’affichage d’un texte à l’écran ou l’accès à une donnée dans une mémoire transactionnelle.
Dans ce qui suit, afin d’introduire ces différentes constructions, je vous propose un exemple simple de calcul à partir d’un nombre que donne l’utilisateur. Je ne détaillerai pas le code en Java, celui-ci étant d’inspiration impérative, approche que ~95% des programmeurs utilisent. Voici ce que donnerait un tel code en Haskell :
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let int = read intAsStr :: Int
putStrLn $ show $ int * int
Pour les lecteurs ne connaissant pas Haskell, le symbole $ est un raccourcis de la mise en parenthèses de ce qui suit ; il inverse le sens de l’évaluation en ce sens qu’elle se fait, à la suite du symbole, de droite à gauche. La fonction read ici convertit l’entrée de l’utilisateur en entier (indiqué par l’instruction :: Int) tandis que la fonction show fait l’opération inverse (il convertit son argument en une chaîne de caractères). (Nous pouvons toutefois remplacer l’instruction putStrLn $ show par la fonction print)
En Java on aurait ceci :
public static void main(String[] args) {
System.out.println("Give me an integer");
Scanner scanner = new Scanner(System.in);
final int number = scanner.nextInt();
System.out.println(number * number);
}
Dans cet exemple, nous multiplions par lui même l’entier donné par l’utilisateur. Tant que l’utilisateur passe un entier tout se passe bien. Mais si jamais celui-ci se trompe et donne, par exemple, des lettres, on aurait aussitôt une exception qui interromprait le programme :
Give me an integer
e4
simple: Prelude.read: no parse
et avec notre programme en Java :
Give me an integer
e4
Exception in thread "main" java.util.InputMismatchException
at java.util.Scanner.throwFor(Scanner.java:864)
at java.util.Scanner.next(Scanner.java:1485)
at java.util.Scanner.nextInt(Scanner.java:2117)
at java.util.Scanner.nextInt(Scanner.java:2076)
at fr.moquillon.fonctors.Simple.main(Simple.java:10)
Pour éviter ce comportement indésirable, en général, il suffit de vérifier ce que donne l’utilisateur et d’agir en conséquence. Ce qui donnerait en Haskell :
displayResultIfInt i
| isInt i = print $ (read i ::Int) * (read i :: Int)
| otherwise = putStrLn "You don't give me an integer :-("
where
isInt s = case reads s :: [(Int, String)] of
[(_, "")] -> True
_ -> False
main = do
putStrLn "Give me an integer"
str <- getLine
displayResultIfInt str
et en Java :
private static void displayResultIfInt(final Scanner reader) {
if (reader.hasNextInt()) {
int i = reader.nextInt();
System.out.println(i * i);
} else {
System.out.println("You don't give me an integer :-(");
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
Scanner scanner = new Scanner(System.in);
displayResultIfInt(scanner);
}
Pour rester simple, le programme ne fait que sortir un message d’erreur si l’utilisateur donne autre chose qu’un entier :
Give me an integer
e4
You don't give me an integer :-(
Toutefois, il y a une autre façon de contrôler les effets de bords indésirables : encapsuler ce que passe l’utilisateur dans une boite afin d’y contraindre les effets de bords et donc éviter qu’elles se répandent dans le reste du programme. Pour notre exemple, si l’utilisateur donne bien un entier, la boite aura cette valeur, sinon elle sera vide puisque, dans notre cas, on ne fera rien avec. Soit en Haskell :
readInt i
| isInt i = Just (read i :: Int)
| otherwise = Nothing
where
isInt s = case reads s :: [(Int, String)] of
[(_, "")] -> True
_ -> False
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let maybeInt = readInt intAsStr
case maybeInt of
Nothing -> putStrLn "You don't give me an integer :-("
Just i -> print $ i * i
Ici, on encapsule ce que passe l’utilisateur dans un objet Maybe qui peut avoir alors deux contextes distinctes : soit il a rien (Nothing), soit il a juste la valeur donnée par l’utilisateur. Voici l’équivalent en Java :
private static Optional<integer> readInt(final Scanner reader) {
if (reader.hasNextInt()) {
return Optional.of(reader.nextInt());
} else {
return Optional.empty();
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
final Optional<integer> optionalInt = readInt(new Scanner(System.in));
if (optionalInt.isPresent()) {
System.out.println(optionalInt.get() * optionalInt.get());
} else {
System.out.println("You don't give me an integer :-(");
}
}
Nous remarquons ici que nous avons mieux structuré notre programme. On contraint tout effet de bord dans une boite (Maybe en Haskell, Optional en Java) et on aiguille le contrôle du programme selon l’état de cette boite. Avant de poursuivre, il existe en Haskell une fonction qui fait déjà ce que notre readInt accomplit mais de façon plus générique : readMaybe
import Text.Read (readMaybe)
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let maybeInt = readMaybe intAsStr :: Maybe Int
case maybeInt of
Nothing -> putStrLn "You don't give me an integer :-("
Just i -> print $ i * i
Maintenant, structurons un peu plus notre programme en y représentant d’une part notre calcul par une fonction spécifique que l’on va appeler compute et d’autre part le traitement du résultat par une autre fonction (ici display) :
import Text.Read (readMaybe)
compute i = i * i
display result =
case result of
Nothing -> putStrLn "You don't give me an integer :-("
Just number -> print number
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let result =
case (readMaybe intAsStr :: Maybe Int) of
Nothing -> Nothing
Just i -> Just $ compute i
display result
et en Java :
private static Optional<integer> readInt(final Scanner reader) {
if (reader.hasNextInt()) {
return Optional.of(reader.nextInt());
} else {
return Optional.empty();
}
}
private static long compute(int i) {
return i * i;
}
private static void display(final Optional<Long> result) {
if (result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("You don't give me an integer :-(");
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
final Optional<Integer> optionalInt = readInt(new Scanner(System.in));
Optional<Long> result;
if (optionalInt.isPresent()) {
result = Optional.of(compute(optionalInt.get()));
} else {
result = Optional.empty();
}
display(result);
}
Nous remarquons que le traitement conditionnel de l’état de notre boite (Maybe en Haskell et Optional en Java) est dupliqué. Ce serait bien d’éviter ceci. En regardant bien le code, nous constatons que le calcul est appliqué que si la boite n’est pas vide, sinon la boite vide est retournée à nouveau. Bref cette dernière instruction apparaît bien inutile. Ce qu’il faudrait ici est une fonction qui préserve la structure de notre boite. La fonction compute étant dans notre cas une opération métier, elle n’a pas à être modifiée pour prendre en compte les particularités de notre code. Il faudrait alors une fonction qui puisse appliquer notre fonction de calcul à la boite même tout en préservant sa structure, sa propre structure de boite : elle retournerait soit une boite vide si celle-ci est vide, soit une boite avec le résultat du calcul. Or, ça tombe bien, il existe une telle fonction aussi bien en Haskell qu’en Java (à partir de Java 8) : c’est la fonction fmap en Haskell (qui définit aussi son équivalent en l’opérateur <$>) :
import Text.Read (readMaybe)
compute i = i * i
display result =
case result of
Nothing -> putStrLn "You don't give me an integer :-("
Just number -> print number
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let result = fmap compute (readMaybe intAsStr :: Maybe Int)
-- ou let result = compute <$> (readMaybe intAsStr :: Maybe Int)
display result
et c’est la méthode map en Java :
private static Optional<integer> readInt(final Scanner reader) {
if (reader.hasNextInt()) {
return Optional.of(reader.nextInt());
} else {
return Optional.empty();
}
}
private static long compute(int i) {
return i * i;
}
private static void display(final Optional<Long> result) {
if (result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("You don't give me an integer :-(");
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
final Optional<Integer> optionalInt = readInt(new Scanner(System.in));
Optional<Long> result = optionalInt.map(FunctorExample::compute);
display(result);
}
Voilà, vous venez d’écrire votre premier foncteur ! En effet, un foncteur n’est rien d’autre qu’une fonction qui applique une autre fonction à des objets dotés d’une structure et qui préserve cette structure. Par analogie avec la théorie des catégories, ces objets sont des morphismes, en l’occurrence, ici en Haskell, Maybe Int pour lesquels fmap conserve bien leur structure de Maybe. Un foncteur est donc toujours relatif à un type de données générique. En Haskell, les foncteurs sont explicites. Ils sont définis par le type algébrique Functor et Maybe est une instance de ce type et spécifie donc comment le foncteur fmap s’applique à elle :
class Functor f where
fmap :: (a -> b) -> f a -> f b
-- | Replace all locations in the input with the same value.
-- The default definition is @'fmap' . 'const'@, but this may be
-- overridden with a more efficient version.
(<$) :: a -> f b -> f a
(<$) = fmap . const
instance Functor Maybe where
fmap _ Nothing = Nothing
fmap f (Just a) = Just (f a)
On dit alors, par extension, que Maybe est un foncteur. Aussi, nous conserverons par la suite cette dénomination aussi bien à la fonction fmap (map en Java) qu’à l’objet sur lequel elle s’applique (en l’occurrence ici Maybe). En Haskell, les fonctions peut aussi être des foncteurs (illustrées ici, avec la fonction fun, via le shell interactif Ghci) :
$ stack ghci
Configuring GHCi with the following packages:
GHCi, version 8.0.2: http://www.haskell.org/ghc/ :? for help
Loaded GHCi configuration from /tmp/ghci5585/ghci-script
Prelude> let i = 3
Prelude> let fun = fmap (*i) (*i)
Prelude> fun 10
90
En Java, les foncteurs sont quant à eux implicitement apportés par la méthode map. Nous pouvons donc dire, par abus de langage, que Optional est implicitement un foncteur (un type applicable par un foncteur). Par contre, contrairement en Haskell, les listes en Java ne sont pas sujettes aux foncteurs mais plutôt les Stream, qui sont une construction générique d’encapsuler des données et d’y appliquer pseudo-paresseusement une chaîne de traitement.
Passons maintenant à la vitesse supérieure et modifions notre opération compute de façon à ce qu’elle accepte désormais deux paramètres au lieu d’un seul. Nous nous trouvons face à une situation où nous ne pouvons plus utiliser notre foncteur tel quel car il ne peut s’appliquer que sur une fonction à un seul paramètre, ce paramètre censé recevoir l’objet encapsulé par notre boite. Voyons ce que donne l’application de fmap avec une fonction à deux paramètres sur notre objet Maybe Int :
$ stack ghci
Configuring GHCi with the following packages:
GHCi, version 8.0.2: http://www.haskell.org/ghc/ :? for help
Loaded GHCi configuration from /tmp/ghci5585/ghci-script
Prelude> i = 3
Prelude> compute i j = i * j
Prelude> :type fmap compute
fmap compute :: (Num a, Functor f) => f a -> f (a -> a)
Prelude> :type fmap compute (Just i)
fmap compute (Just i) :: Num a => Maybe (a -> a)
Nous remarquons qu’une autre boite est retournée avec … une fonction à un paramètre dedans (en Haskell, a -> a est la signature d’une fonction à un paramètre qui retourne un valeur de même type). En Haskell, toute fonction à plusieurs paramètres peut se résumer à une fonction à un seul paramètre qui retourne une fonction qui s’applique avec les autres paramètres (et ainsi de suite) ; c’est ce que l’on appelle la curryfication (du nom du mathématicien Haskell Curry) et fmap ne fait rien d’autre que curryfier la fonction compute et comme elle préserve la structure de Maybe, elle retourne donc ici un Maybe (Int -> Int) (une boite Maybe avec une fonction à un paramètre dedans). En partant de ce constat, on pourrait étendre notre code existant avec une fonction qui sache appliquer une fonction encapsulée dans une boite (en l’occurrence ici un Maybe (Int -> Int)) sur notre Maybe Int. Or, justement il existe une telle fonction en Haskell (ou plus exactement un tel opérateur) : <*>.
import Text.Read (readMaybe)
-- fonction à deux paramètres Int qui retourne un Int
-- (ou encore un fonction à un paramètre Int qui retourne une fonction à un paramètre Int)
compute :: Int -> Int -> Int
compute i j = i * j
display result =
case result of
Nothing -> putStrLn "You don't give me an integer :-("
Just number -> print number
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let maybeInt = readMaybe intAsStr :: Maybe Int
let result = fmap compute maybeInt <*> maybeInt
display result
Vous venez là aussi d’écrire votre premier foncteur applicatif ! En effet, <*> n’est rien d’autre qu’un foncteur applicatif (applicative en anglais). Sachant qu’ici fmap compute définit en quelque part un type de foncteurs, on peut écrire qu’un foncteur applicatif est un foncteur de foncteurs. Maintenant, comment écrire ceci en Java, sachant que les foncteurs applicatifs et la curryfication n’y existent pas. Nous pouvons nous inspirer du code Haskell pour accomplir la même chose :
public class ApplicativeExample {
private static Optional<Integer> readInt(final Scanner reader) {
if (reader.hasNextInt()) {
return Optional.of(reader.nextInt());
} else {
return Optional.empty();
}
}
private static long compute(int i, int j) {
return i * j;
}
private static Function<Integer, Long> curryfiedCompute(final int i) {
return j -> compute(i, j);
}
private static Optional<Function<Integer, Long>> computeFunctor(Optional<Integer> optionalInt) {
return optionalInt.map(ApplicativeExample::curryfiedCompute);
}
private static <T, R> Optional<R> applicativeMap(Optional<Function<T, R>> optionalFunction,
Optional<T> optionalParameter) {
if (optionalParameter.isPresent() && optionalFunction.isPresent()) {
return Optional.ofNullable(optionalFunction.get().apply(optionalParameter.get()));
} else {
return Optional.empty();
}
}
private static void display(final Optional<Long> result) {
if (result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("You don't give me an integer :-(");
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
final Optional<Integer> optionalInt = readInt(new Scanner(System.in));
Optional<Long> result = applicativeMap(computeFunctor(optionalInt), optionalInt);
display(result);
}
}
Pour simplifier le code et rendre réutilisable les foncteurs applicatifs, nous pouvons réécrire la classe Optional pour qu’elle puisse supporter les foncteurs applicatifs :
public class ApplicativeOptional<T> {
...
public <U> ApplicativeOptional<U> appMap(ApplicativeOptional<Function<? super T, ? extends U>> mapper) {
Objects.requireNonNull(mapper);
if (isPresent() && mapper.isPresent()) {
return ofNullable(mapper.get().apply(value));
} else {
return empty();
}
}
...
}
et utiliser cette nouvelle classe dans notre exemple :
public class ApplicativeExample {
private static ApplicativeOptional<Integer> readInt(final Scanner reader) {
if (reader.hasNextInt()) {
return ApplicativeOptional.of(reader.nextInt());
} else {
return ApplicativeOptional.empty();
}
}
private static long compute(int i, int j) {
return i * j;
}
private static Function<Integer, Long> curryfiedCompute(final int i) {
return j -> compute(i, j);
}
private static void display(final ApplicativeOptional<Long> result) {
if (result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("You don't give me an integer :-(");
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
final ApplicativeOptional<Integer> optionalInt = readInt(new Scanner(System.in));
ApplicativeOptional<Long> result = optionalInt.appMap(optionalInt.map(ApplicativeExample::curryfiedCompute));
display(result);
}
}
En Haskell, comme pour les foncteurs, les foncteurs applicatifs sont définis par un type algébrique, ici Applicative et là aussi Maybe est une instance de celui-ci :
class Functor f => Applicative f where
{-# MINIMAL pure, ((<*>) | liftA2) #-}
-- | Lift a value.
pure :: a -> f a
-- | Sequential application.
--
-- A few functors support an implementation of '<*>' that is more
-- efficient than the default one.
(<*>) :: f (a -> b) -> f a -> f b
(<*>) = liftA2 id
-- | Lift a binary function to actions.
--
-- Some functors support an implementation of 'liftA2' that is more
-- efficient than the default one. In particular, if 'fmap' is an
-- expensive operation, it is likely better to use 'liftA2' than to
-- 'fmap' over the structure and then use '<*>'.
liftA2 :: (a -> b -> c) -> f a -> f b -> f c
liftA2 f x = (<*>) (fmap f x)
...
instance Applicative Maybe where
pure = Just
Just f <*> m = fmap f m
Nothing <*> _m = Nothing
liftA2 f (Just x) (Just y) = Just (f x y)
liftA2 _ _ _ = Nothing
Just _m1 *> m2 = m2
Nothing *> _m2 = Nothing
Nous constatons que pour qu’un type soit applicable par un foncteur applicatif, il faut qu’il le soit déjà par un foncteur (logique !). Par extension, on dit que Maybe est aussi un foncteur applicatif. On remarque aussi l’existence d’une fonction liftA2, basée sur <*>, qui permet de simplifier l’écriture de notre programme en prenant en compte directement les fonctions à deux paramètres et les appliquer à deux foncteurs :
import Control.Applicative (liftA2)
import Text.Read (readMaybe)
compute i j = i * j
display result =
case result of
Nothing -> putStrLn "You don't give me an integer :-("
Just number -> print number
main = do
putStrLn "Give me an integer"
intAsStr <- getLine
let maybeInt = readMaybe intAsStr :: Maybe Int
let result = liftA2 compute maybeInt maybeInt
display result
De la même manière, nous pourrions aussi écrire en Java un équivalent à liftA2 :
public class ApplicativeOptional<T> {
...
public <U, R> ApplicativeOptional<R> biLift(final BiFunction<T, U, R> mapper, ApplicativeOptional<U> param) {
if (param.isPresent() && this.isPresent()) {
return ApplicativeOptional.ofNullable(mapper.apply(this.get(), param.get()));
} else {
return ApplicativeOptional.empty();
}
}
...
et l’utiliser dans notre programme :
public static void main(String args[]) {
System.out.println("Give me an integer");
final ApplicativeOptional<Integer> optionalInt = readInt(new Scanner(System.in));
ApplicativeOptional<Long> result = optionalInt.biLift(ApplicativeExample::compute, optionalInt);
display(result);
}
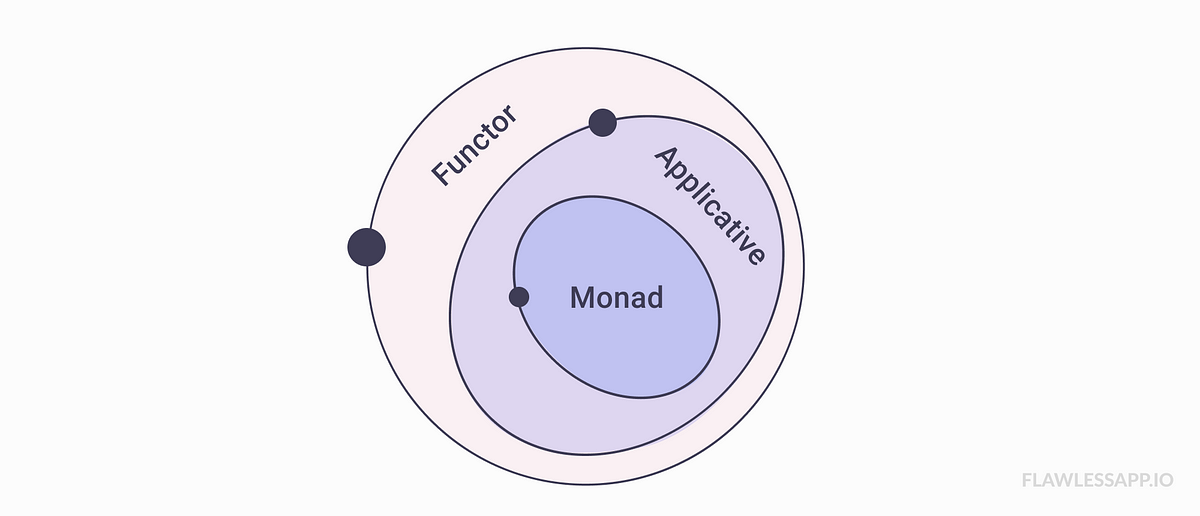
Nous avons donc vu ce qu’était un foncteur et un foncteur applicatif (un foncteur de foncteurs) et à quels usages ils répondaient. Un foncteur pourra être utilisé pour appliquer des fonctions à des objets dotés d’une structure interne et conserver celle-ci sans avoir à accéder directement aux détails de cette structure. De tels objets sont, comme nous l’avons vu, en général des types génériques qui véhiculent un contexte. Un foncteur applicatif n’est rien d’autre qu’une extension des foncteurs aux fonctions mêmes et permet de pouvoir appliquer une boite avec une fonction sur une boite avec une valeur. Ceci est utile lorsqu’il s’agit d’appliquer, comme dans notre exemple, des fonctions à plusieurs paramètres sur un objet doté d’une structure, mais il peut être aussi utilisé avec des fonctions obtenues à partir d’un autre traitement contextuel.
Ne nous arrêtons pas pour autant là et continuons de faire évoluer notre programme. Imaginons maintenant que notre fonction compute a un comportement distinct en fonction de ses paramètres. Par exemple, qu’elle n’effectue son opération qu’avec les entiers positifs :
compute :: Int -> Int -> Maybe Int
compute i j
| i < 0 || j < 0 = Nothing
| otherwise = Just $ i * j
Cette fois ci, compute retourne une boite avec potentiellement le résultat du calcul, sinon rien. A première vue fmap compute devrait retourner un foncteur avec notre fonction compute curryfiée. Or comme cette dernière accepte comme paramètre un simple entier, l’opérateur <*> devrait pouvoir l’appliquer à notre Maybe Int. Sachant de plus que l’opérateur <*> préserve la structure de notre boite Maybe Int auquel il est appliqué, et que la fonction curryfiée retourne elle-même une boite, on est en droit à s’attendre à ce que l’application de l’opérateur retourne un Maybe (Maybe Int), résultat que ne saurait interpréter la fonction display telle qu’elle est écrite. Vérifions ceci :
Configuring GHCi with the following packages:
GHCi, version 8.0.2: http://www.haskell.org/ghc/ :? for help
Loaded GHCi configuration from /tmp/ghci9751/ghci-script
Prelude> compute i j | i < 0 && j < 0 = Nothing | otherwise = Just $ i * j
Prelude> fmap compute (Just 3) <*> Just 3
Just (Just 9)
C’est bien le cas. Or, ce que l’on voudrait c’est en retour un Maybe Int. L’idée ici est soit de trouver une fonction en lieu et place de <*> qui fasse ça tout seul, soit étendre comme précédemment notre composition fonctionnelle en y introduisant une autre fonction qui, à partir d’une boite de boite, retourne la boite contenue. Et ça tombe bien parce qu’Haskell fournit une telle fonction, ou plus exactement un tel opérateur (là aussi) : >>=. Voyons ce que cela donne :
import Text.Read (readMaybe)
compute :: Int -> Int -> Maybe Int
compute i j
| i < 0 || j < 0 = Nothing
| otherwise = Just $ i * j
display result =
case result of
Nothing -> putStrLn "You don't give me a positive integer :-("
Just number -> print number
main = do
putStrLn "Give me a positive integer"
intAsStr <- getLine
let maybeInt = readMaybe intAsStr :: Maybe Int
let result = fmap compute maybeInt <*> maybeInt >>= id
display result
Afin d’obtenir juste ce que contient la boite Maybe (Maybe Int), c’est-à-dire Maybe Int, nous appliquons l’opérateur >>= directement sur la fonction identité id. Il existe toutefois une fonction qui fait déjà ceci : join.
import Text.Read (readMaybe)
import Control.Monad (join)
compute :: Int -> Int -> Maybe Int
compute i j
| i < 0 || j < 0 = Nothing
| otherwise = Just $ i * j
display result =
case result of
Nothing -> putStrLn "You don't give me a positive integer :-("
Just number -> print number
main = do
putStrLn "Give me a positive integer"
intAsStr <- getLine
let maybeInt = readMaybe intAsStr :: Maybe Int
let result = join $ fmap compute maybeInt <*> maybeInt
display result
Voilà, nous venons d’introduire le concept de monade. Une monade n’est pas cette fois-ci un morphisme comme le sont les foncteurs et les foncteurs applicatifs mais plutôt une construction, un type algébrique abstrait, reposant sur les foncteurs et qui est défini par les propriétés suivantes :
- il existe une correspondance qui à tout type générique relie un type monadique ; autrement dit, par simplification, un constructeur qui à une valeur retourne une monade avec cette valeur. Dans notre exemple,
fmap computeretourne une monade avec un tel constructeur (la fonctioncomputecurryfiée) ; - il existe une opération de composition interne associative entre monades sous forme d’un foncteur, donc qui préserve la structure monadique. Dans notre exemple, il s’agit de
>>=; - il existe un élément neutre, appelé identité. Dans le cas des
Maybe a, c’estNothing.
Une monade est une application aux catégories (en gros, dans notre cas, aux foncteurs) ce que sont les monoïdes en algèbre (qui sont des ensembles munis d’une loi de composition interne associative et d’un élément neutre). D’où le nom de monade. En Haskell, comme pour les foncteurs et les foncteurs applicatifs, les monades sont définis explicitement par un type algébrique, Monad et, comme on s’en est douté, Maybe est aussi une instance de celui-ci :
class Applicative m => Monad m where
-- | Sequentially compose two actions, passing any value produced
-- by the first as an argument to the second.
(>>=) :: forall a b. m a -> (a -> m b) -> m b
-- | Sequentially compose two actions, discarding any value produced
-- by the first, like sequencing operators (such as the semicolon)
-- in imperative languages.
(>>) :: forall a b. m a -> m b -> m b
m >> k = m >>= \_ -> k -- See Note [Recursive bindings for Applicative/Monad]
{-# INLINE (>>) #-}
-- | Inject a value into the monadic type.
return :: a -> m a
return = pure
...
instance Monad Maybe where
(Just x) >>= k = k x
Nothing >>= _ = Nothing
(>>) = (*>)
...
Donc, pour qu’un type soit une monade il faut qu’il soit applicable aux foncteurs applicatifs et donc aux foncteurs. En l’occurrence, Maybe est une monade.
A l’image des foncteurs applicatifs, il existe une méthode liftM2 que nous pouvons ici utiliser pour simplifier notre code :
import Text.Read (readMaybe)
import Control.Monad (liftM2)
compute :: Int -> Int -> Maybe Int
compute i j
| i < 0 || j < 0 = Nothing
| otherwise = Just $ i * j
display result =
case result of
Nothing -> putStrLn "You don't give me a positive integer :-("
Just number -> print number
main = do
putStrLn "Give me a positive integer"
intAsStr <- getLine
let maybeInt = readMaybe intAsStr :: Maybe Int
let result = liftM2 compute maybeInt maybeInt
display result
N’avez vous pas trouvé une ressemblance de l’opérateur >>= avec celui <$>, autrement dit avec la fonction équivalente fmap ? En fait, tout simplement, l’opérateur >>= n’est rien d’autre que ce que l’on appelle un flat map. En partant de ce constat, il est alors relativement simple d’écrire un code équivalent en Java. La classe Optional dispose de la méthode flatMap mais ne supporte pas les foncteurs applicatifs. Aussi créons une nouvelle classe, MonadicOptional, qui soit sujet non seulement aux foncteurs applicatifs mais aussi au flat map :
public final class MonadicOptional<T> {
...
public <U> MonadicOptional<U> appMap(MonadicOptional<Function<? super T, ? extends U>> mapper) {
Objects.requireNonNull(mapper);
if (isPresent() && mapper.isPresent()) {
return ofNullable(mapper.get().apply(value));
} else {
return empty();
}
}
public <u> MonadicOptional<U> flatMap(Function<? super T, MonadicOptional<U>> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Objects.requireNonNull(mapper.apply(get()));
}
}
...
}
puis utilisons le dans notre programme :
public class MonadExample {
private static MonadicOptional<Long> compute(int i, int j) {
if (i < 0 && j < 0) {
return MonadicOptional.empty();
}
return MonadicOptional.ofNullable((long) (i * j));
}
private static Function<Integer, MonadicOptional<Long>> curriedCompute(final int i) {
return j -> compute(i, j);
}
private static MonadicOptional<Integer> readInt(final Scanner reader) {
if (reader.hasNextInt()) {
return MonadicOptional.of(reader.nextInt());
} else {
return MonadicOptional.empty();
}
}
private static void display(final MonadicOptional<Long> result) {
if (result.isPresent()) {
System.out.println(result.get());
} else {
System.out.println("You don't give me an integer :-(");
}
}
public static void main(String args[]) {
System.out.println("Give me an integer");
final MonadicOptional<Integer> optionalInt = readInt(new Scanner(System.in));
MonadicOptional<long> result = optionalInt.appMap(optionalInt.map(MonadExample::curriedCompute)).flatMap(Function.identity());
display(result);
}
}
En conclusion, les foncteurs et les foncteurs applicatifs sont les briques de base nécessaire à la conception des monades dont l’intérêt est finalement de pouvoir chaîner des actions sur un type générique doté d’une structure tout en conservant celle-ci. Les monades établissent l’ensemble des propriétés que doivent vérifier de tels types génériques, permettant ainsi de les manipuler sans avoir à casser, pour ce faire, leur structure et répandre ainsi leur contexte dans tout le programme (les effets de bords), perdant ainsi potentiellement le contrôle sur celui-ci et ouvrant la voie à des bogues potentiels, et limitant aussi l’évolution et l’extension du code.
Vous comprenez maintenant aussi d’où proviennent les map et les flat map et, par extension, le map-reduce. Il est toutefois dommage que de telles constructions, en provenance de la programmation fonctionnelle, soit récupérées et intégrées dans les langages impératifs, comme Java, sans comprendre, et donc prendre en compte, l’essence même de celles-ci. C’est ce qui explique pourquoi elles apparaîssent si limitées et donc fustrantes à utiliser dans certains contextes avec des langages comme Java.
Pour finir, j’espère que ce billet aura été explicite dans sa présentation de ce que sont les foncteurs, les foncteurs applicatifs, et les monades et que de là vous ayez une meilleur compréhension de ce qu’ils peuvent apporter dans vos programmes.