Conception d'applications Web :
Petite analyse UML

Ceci est le début d'une série d'articles sur la conception d'applications Web avec différentes plate-formes ; on y retrouvera, entre autre, la plate-forme Java et celle Ruby On Rails.
La conception d'un blog sera pris comme exemple d'application Web dans chacun des articles. Et pour commencer, cet article présente l'application à développer sous forme de diagrammes UML.
1. Introduction
Au début, je désirais juste écrire un article sur le développement d'une application Web en Java avec un certain nombre de framework : Wicket, Spring, JPA, et Hibernate. Puis, avec le désir de tester d'autres plate-formes de développement d'application Web, et plus particulièrement Seaside, je me suis alors dis que ça pouvait être l'occasion de définir une application Web simple et de la décliner sur chacune des plate-formes à tester.
Nous allons donc présenter dans cet article l'application Web choisie pour chacune des plate-formes : un blog !2. Les fonctionnalités
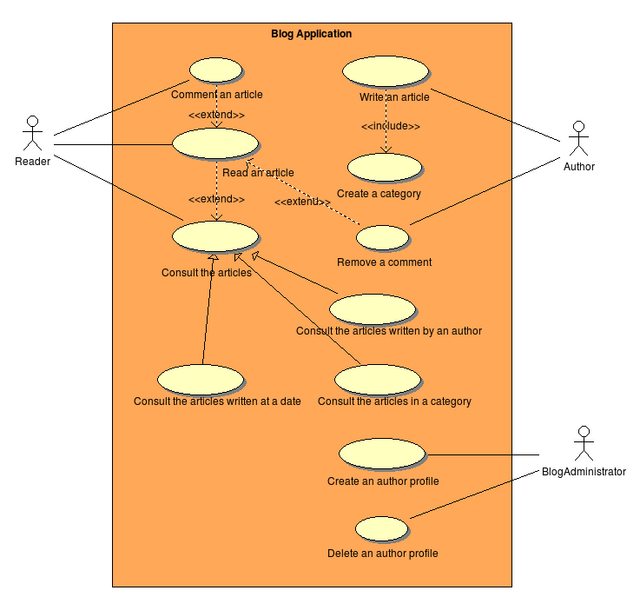
Le système étudié ici est le blog. Un blog est une application qui permet à des personnes, les rédacteurs, de rédiger des articles à destination de lecteurs passagers. Ces derniers peuvent y déposer des commentaires sur l'article lu. A la lecture donc de ce petit exposé, nous identifions potentiellement deux types d'utilisateurs d'un blog : les rédacteurs (auteurs des articles) et les lecteurs. Dans UML, un type d'utilisateur est dît acteur car il agît (il acte) sur le système. De la même façon, nous avons déjà identifié deux types d'objets sur lesquels le blog porte : l'article et le commentaire ; ce sont les objets d'interaction entre le système et les utilisateurs, ils font donc partie de l'interface d'utilisation de l'application.
Dans ce qui suit, nous allons détailler chaque type d'utilisation du blog par les rédacteurs et les lecteurs dans un tableau. C'est ce que l'on appelle des cas d'utilisation du système, et à chaque cas d'utilisation correspond une fonctionnalité de l'application. Par exemple, la consultation des articles du jour par un lecteur est un cas d'utilisation du blog ; l'application doit alors offrir comme fonctionnalité la présentation de tout ou partie de chaque article du jour du blog sur une seule page. Les cas d'utilisations sont illustrés dans le diagramme UML ci-dessus. Le système est considéré ici comme une boite noire.
| Cas d'utilisation | Description courte | Contraintes |
|---|---|---|
| Consulter des articles | Une page présente une suite d'articles (titre, auteur, date, catégorie, début du texte) répondant à un critère précis :
|
|
| Lire un article |
Une page présente le contenu complet de l'article, accompagné des commentaires des lecteurs sur l'article. Ce cas d'utilisation est une extension de la consultation d'articles. |
|
| Commenter un article |
Un bouton est proposé au lecteur pour y laisser un commentaire. Lorsqu'il est cliqué, une page d'édition est présentée au lecteur avec une fonction de prévisualisation et une fonction de validation. La validation entraîne l'enregistrement du commentaire. Ce cas d'utilisation est une extension de la lecture d'un article. |
|
| Rédiger un article | Tout rédacteur peut saisir un nouvel article dans son espace du blog. Celui-ci présente une page d'édition pour ce faire avec une fonction de prévisualisation et une fonction de validation. La validation entraîne l'enregistrement de l'article qui sera alors accessible par tout lecteur. Lors de la rédaction de l'article, l'auteur est invité à choisir une ou plusieurs catégories de celui-ci. Si une catégorie n'existe pas, elle est alors automatiquement créée. |
|
| Supprimer un commentaire |
L'auteur d'un article peut à tout moment et sans se justifier supprimer un ou plusieurs commentaires à ses articles. Ce cas d'utilisation est une extension de la lecture d'un article. |
|
| Créer une catégorie | Ce cas d'utilisation est incluse dans la rédaction d'un nouvel article. Lorsqu'un rédacteur choisi pour son article en cours de rédaction des catégories qui n'existent pas encore, elles sont créées au sein du blog. |
|
| Créer un compte rédacteur | Afin de pouvoir écrire des articles, un utilisateur du blog doit disposer d'un compte de rédacteur sur ledit blog. La création d'un tel compte est à la discrétion ici du gestionnaire du blog (l'administrateur de l'application). Une page d'administration est proposée pour la création et pour lister les comptes des rédacteurs. |
|
| Supprimer un compte rédacteur | L'administrateur de l'application a toute latitude de supprimer un compte de rédacteur existant. Une page d'administration permet de lister tous les comptes existant et de les supprimer. |
|
Les cas d'utilisation présentés ici ne sont pas évidemment exhaustives mais seront celles que nous tâcheront de réaliser dans les différents articles de cette série.
3. Le domaine
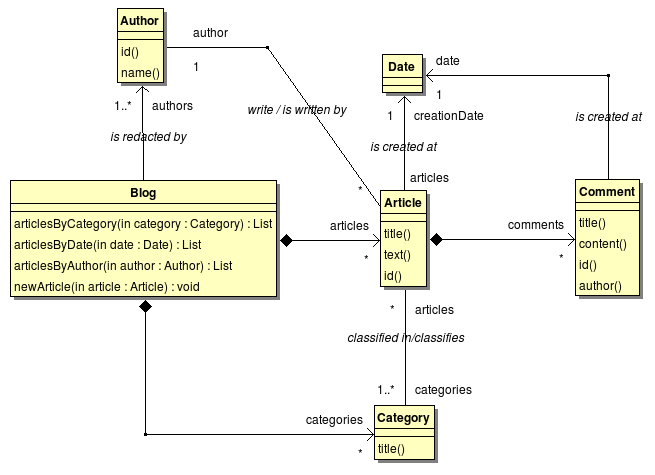
Des cas d'utilisation décrites dans la section précédente, nous avons déjà identifié trois classes d'objets : les articles, les commentaires et les catégories. Ce sont des objets que manipulent les utilisateurs de l'application. De même, nous avons identifié trois types d'utilisateurs : le rédacteur (ou auteur d'articles), le lecteur et l'administrateur du blog. Le rédacteur et l'administrateur sont des utilisateurs authentifiés au sein du système. A ce titre, ils ont leur représentation sous forme d'objet du domaine. De ces objets identifiés au travers des cas d'utilisation du système, reste à définir leurs associations.
Le diagramme de classe UML ci-dessus définit les classes d'objets et leur relation dans le domaine du blog. De celui-ci, nous pouvons dire qu'un blog est constitué d'une liste ordonnée dans le temps d'articles, d'un ensemble de rédacteurs et de catégories.
Les messages que comprennent les différents classes d'objets ont été écris sous forme de méthodes UML sans attachament à une règle d'écriture d'un langage de programmation particulier.
Un article est rédigé par un auteur à une date de rédaction donnée (la propriété creationDate et porte sur divers sujets, chacun d'entre eux représenté par une catégorie. Un article peut être commenté à différentes date par des lecteurs.
Un auteur peut écrire plusieurs articles dans le temps. Une catégorie permet de classifier les articles entre eux.
Le blog permet, grâce aux associations entre les différents objets du domaine, de retrouver les articles sur un sujet, à une date donnée ou écrit par un autre précis. Lorsque l'article est retrouvé, les commentaires associés sont aussi retournés.
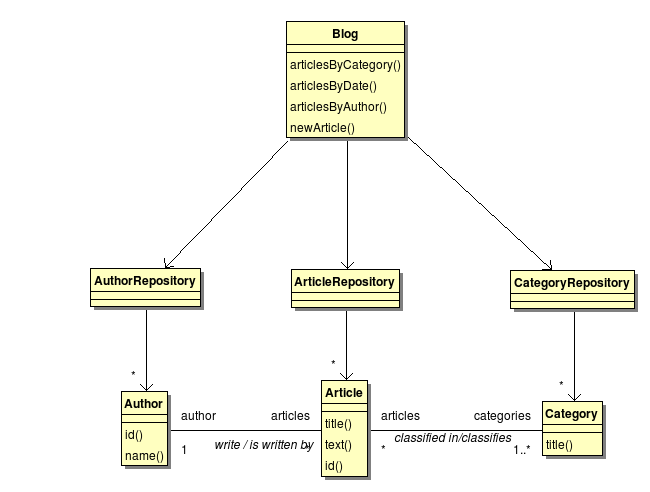
Le blog pouvant contenir de très nombreux articles, auteurs et catégories, il est nécessaire que ce dernier ne référence pas directement l'ensemble de ces objets disponibles. Il est donc utile de disposer d'un dépôt pour chacun de ces types d'objets ; ce qui permettra, selon les frameworks utilisés, une association, et donc une récupération, paresseuse. Ces dépôts d'objet encapsulent la façon dont sont rééllement sérialisés nos objets de façon à pouvoir les récupérer quelque soit le contexte d'exécution. La création de nos objets ne relève pas des attributions des dépôts ; elle sera à la charge d'usines à objets (factory en anglais). Ce modèle de conception est tiré de l'approche Domain Driven Design.
4. Conclusion
Cet article a présenté l'application Web que nous allons par la suite réalisée dans différentes technologies. Il est évident que sur certaines plates-formes, la réalisation des objets du domaine sera simplifiée, que les dépôts ne seront pas représentés comme des classes distinctes des classes métiers, etc.


